

Multimodal Foundation Models
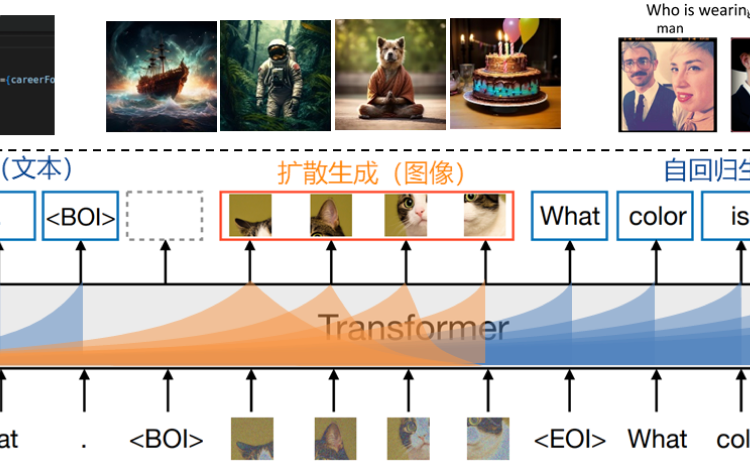
Multimodal Foundation Models
We aim to develop a comprehensive multimodal foundation model capable of handling a wide range of tasks across diverse modalities, including text, image, and video understanding and generation. The model will be designed for easy adaptation to various downstream applications and scenarios.Our research will focus on advancing the architecture of the foundation model, optimizing multimodal training algorithms, improving inference accuracy and efficiency, and exploring real-world applications.

AIGC Theory and Algorithms

AIGC Theory and Algorithms
We aim to advance the theoretical foundations and algorithmic innovations in the field of Artificial Intelligence Generated Content (AIGC). By delving deeply into the theoretical analysis of AIGC algorithms, we seek to uncover the principles underlying generative architectures, optimize training frameworks, accelerate inference, and enhance both controllability and interpretability.
lmage & Video & 3DGeneration and Application

Image & Video & 3D Generation and Application
Our research is centered on leveraging AI-Generated Content (AIGC) models, with a spotlight on diffusion models, to craft high-fidelity, realistic images, videos, and 3D content. We're striving to evolve these models into a generative world model that intricately mirrors the nuances of the real world, setting the stage for breakthroughs in creative industries like entertainment, virtual reality, and digital interaction.